Binary search in BASIC DATA statements
Behold! Binary search of five-letter words in BASIC DATA statements without pre-processing the memory! gist.github.com/dansanderson/8…
The DATA region must start with a word count, followed by the words in a specific format: line number, DATA, space, then five words per line, comma-delimited without spaces or quotes.

The formatting is important because this hack manipulates the DATPTR, a pointer into BASIC memory that indicates where the previous READ left off. We initialize by reading the word count, then storing DATPTR as a base address for the word data. (Also shown: demo queries.)

Subroutine 1100 performs the random access of the I-th word by calculating and setting DATPTR, then READing into W$.

The nonsense on line 1111 is needed because 1110 finds the character before the word. READ doesn’t like DATPTR set to the space before the first word on a line, so I test for this and rewind to the previous line terminator, which is where a natural READ would leave it.
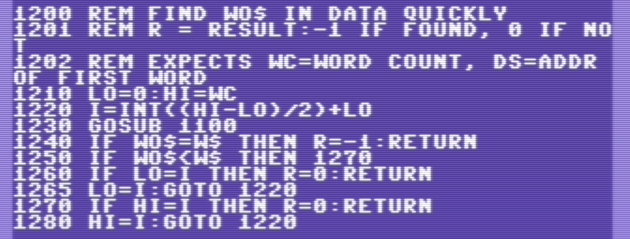
Subroutine 1200 is the binary search. This is intuitive! The random access does the hard part, so this is just indexing by element ID. BASIC 2.0 can do string comparison with the <,>,= operators. (-1 is true, 0 is false.)
Here are the results of those test queries.
The next step would be to performance test on a large word list, but I’m confident that the binary search is O(log n) and shouldn’t be much slower with a much larger list.

This does still chug a bit because of all the READs and string comparisons. Many programs with DATA statements get all of the data out into a more useful data structure in an initialization pass. AFAIK, hacking DATPTR is an unusual technique for random access.
Idea: Read the whole table, but instead of copying the strings out of the table into an array, make an array of DATPTR derived pointers of the words in BASIC memory. Use a custom string compare, or maybe reuse the KERNAL compare directly on the RAM? Saves on re-parsing.
(Originally posted to Twitter on January 26, 2022. It received 6 likes.)